








Some authors are suing to prevent AI from "ingesting" more work. Is it too late?
AI can’t “learn” unless it has something to train on. Authors Mona Awad and Paul Tremblay are suing OpenAI on the grounds that ChatGPT, an OpenAI product, used their copyrighted material to improve the model, reports The Guardian:
Books are ideal for training large language models because they tend to contain “high-quality, well-edited, long-form prose,” said the authors’ lawyers, Joseph Saveri and Matthew Butterick, in an email to the Guardian. “It’s the gold standard of idea storage for our species.”
It’s the beginning of the legal AI wars, as a Harvard Business Review article from earlier this year noted. In the piece, the authors explained how AI works:
Generative AI platforms are trained on data lakes and question snippets — billions of parameters that are constructed by software processing huge archives of images and text. The AI platforms recover patterns and relationships, which they then use to create rules, and then make judgments and predictions, when responding to a prompt.
It just so happens that the AI platforms love to taunt us once they get going. As the saying goes, the machines weren’t born wanting to kill; we taught them to desire it with our dark, dark history of speculative fiction (less a quip than something I made up just now). You know Jaron Lenier saw it coming.
Beyond the notion of artists and writers becoming mere generative tools for the dark net, one issue this lawsuit brings up is that even if novelists succeed in “protecting” their work from AI, any public conversation about their work would likely still be fair game. Awad and Tremblay’s lawyers also say that the models used to train AI models also use “shadow libraries” containing almost 300,000 titles. So, it’s a problem. What to do?
I texted my friend, who is a fancy IP attorney, to see if there were some accessible solutions that don’t involve multi-million-dollar lawsuits:
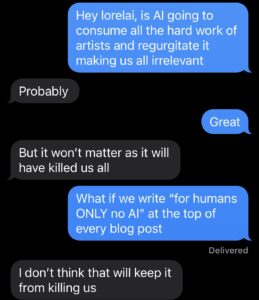
I’m sorry I don’t have better news.
Another friend who is also an IP attorney thinks perhaps literature will move toward a licensing model, like music. Really looking forward to that Spotify money.
Janet Manley
Janet Manley is a contributing editor at Literary Hub, and a very serious mind indeed. Get her newsletter here.








